QIMING 920 AI Chip (MUSEv2 Architecture)
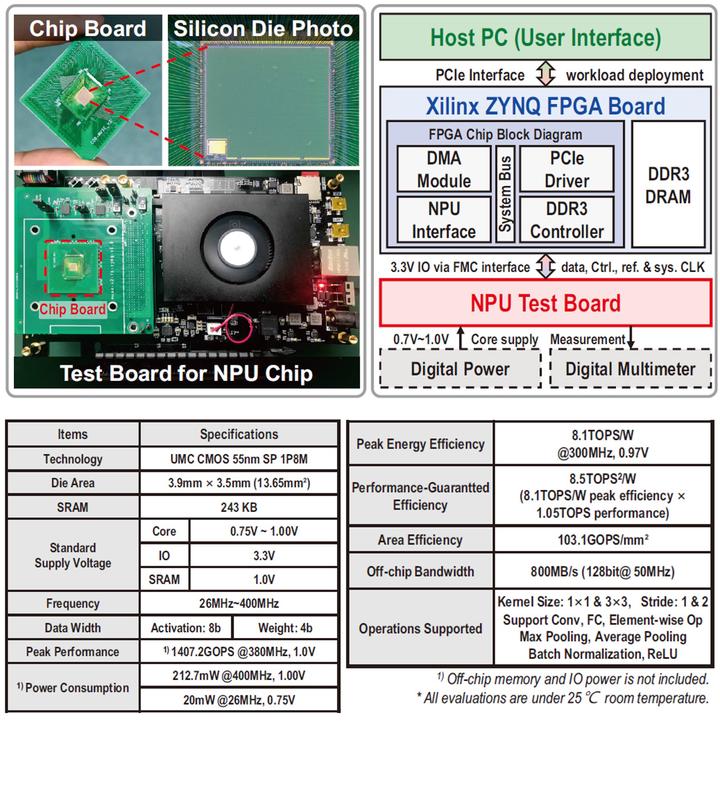
To further improve the dataflow and flexibility of QIMING-910, I proposed the architecture of QIMING-920 in the summer of 2019. During the fabrication of QIMING-910, I found its instruction design was not user-friendly, which made it hard to deploy a larger model. On the top of that, the bit-width of the partial-sum register was not enough, leading to a significant accuracy drop for the ImageNet dataset. Therefore, it is necessary to design a next-generation architecture for 920.
First, I improved the pattern-based pipeline to overlap the data loading as far as possible. For the ALU design, I generalized the computation flow for three quantization modes and increased the bit-width of the partial-sum register to avoid overflow. I also modified the activation buffer to support the kernel-wise pruning.
Based on MSUEv2, QIMING-920 is a real “MUlti-grained Sparsity Engine” that supports channel-wise, kernel-wise, pattern-wise pruning and linear, power-of-two, mixed-power-of-two quantization. This work was presented in CICC 2021.